Scraping tabular data with pdfplumber
I got distracted by this toot:
A bot that automatically does stock trades …
… by identifying trades being done by US politicians …
… who probably have inside (I.e. and thus basically illegal-to-act-upon) knowledge of market-moving government info …
… and doing the same trades
He’s up 20% since May 2022
The idea you can track insider trading through the financial disclosure reports of politicians is very appealing. I gave myself a weekend challenge to reproduce the trading strategy. Inevitably, I didn’t finish writing the bot, but I did find that extracting data from PDF tables has got easier since I last tried, so here are some notes.
Specifically: pdfplumber provides all the things you need. I found it
somewhat difficult to follow the documentation; the most helpful thing is this walkthrough.
pdfplumber uses various heuristics that work remarkably well to infer cells of
data. It looks for graphical elements, and failing that, looks for vertical (or
horizontal) word alignments.
The table I’m interested in doesn’t have natural vertical delimiters: some of the rows have text that overflows into adjacent “cells”. You can see that in the “COMMENTS” section here:
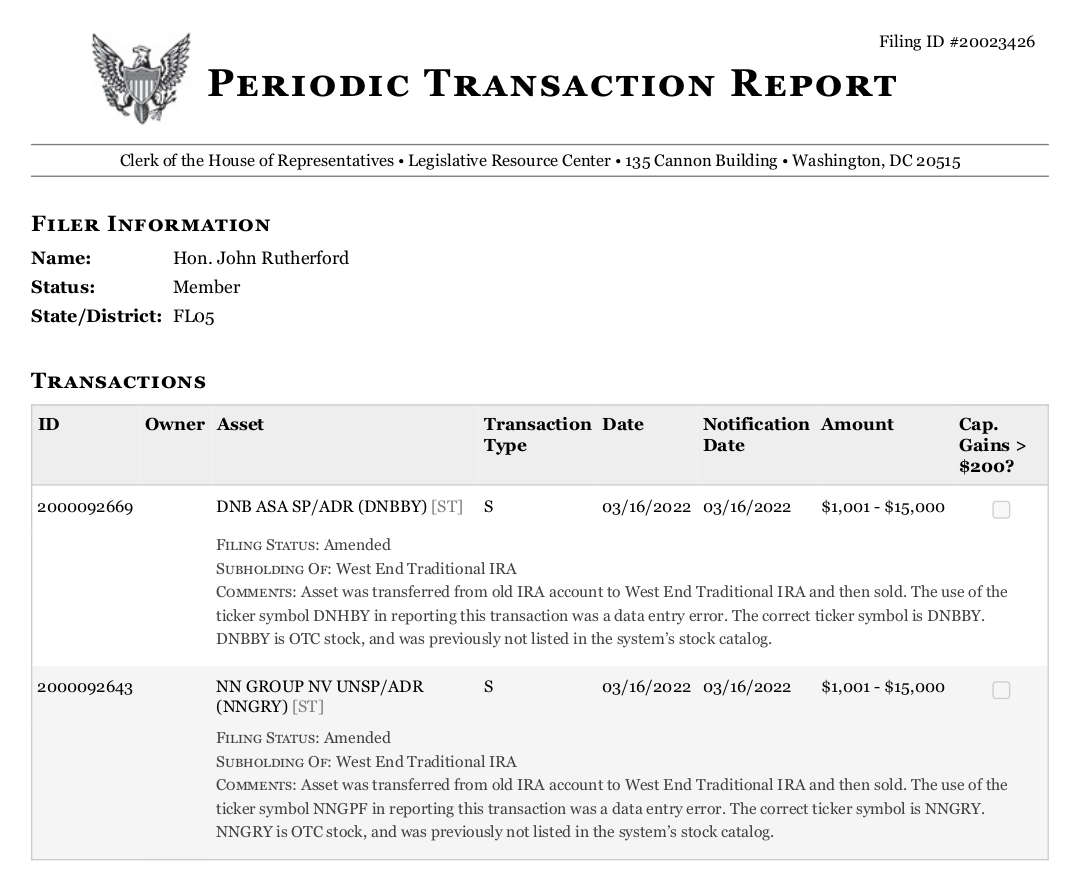
So I wrote code to:
- find the header, which is present in all examples of this table;
- find the vertical delimiters for that;
- use those delimiter locations as explicit values for extracting cells from the rest of the table
Like this:
import pdfplumber
import re
def locate_table_columns(pdf_page):
"""
Finds the coordinates of table columns on a PDF page.
The function locates the words 'Owner' and '$200?' to define the bounds of the
header row, which helps in determining the columns' coordinates for table extraction.
"""
words_on_page = pdf_page.extract_words()
# Finding specific header keywords to locate the entire header row
owner_header = next((word for word in words_on_page if word["text"] == "Owner"), None)
value_header = next((word for word in words_on_page if "$200?" in word["text"]), None)
if owner_header and value_header:
# Extract a bounding box
bbox = [owner_header["x0"], owner_header["top"], value_header["x1"], value_header["bottom"]]
cropped_header = pdf_page.crop(bbox)
# Find the bounding boxes of the words _within_ the header
words_in_header = cropped_header.extract_words(
keep_blank_chars=True, # do not tokenize on spaces, i.e. fit entire lines in 1 box
y_tolerance=20, # fit words wrapped over several lines in 1 box
)
column_coords = [round(word["x0"]) for word in words_in_header]
return column_coords
else:
print("No table found on the page.")
def convert_pdf_to_csv(pdf_filename):
with pdfplumber.open(pdf_filename) as pdf:
for page in pdf.pages:
column_coords = locate_table_columns(page)
if not column_coords:
continue
extracted_table = page.extract_table(
table_settings={
"vertical_strategy": "explicit",
"explicit_vertical_lines": column_coords,
}
)
Postscript 1: it turns out the automatic extraction of the text was actually good enough, and I didn’t need any of that.
Postscript 2: In the House of Representatives, there’s only 33 representatives in the last two years who registered buy and sell activity of the same stock. Seems like that might be the best indicator of insider trading, in which case it doesn’t feel like a particularly rich dataset. By that measure, the most active trader by far was Michael C. Burgess (Rep) with 32 buy/sell trades in the last two years. The fastest trader was Josh Gottheimer (Dem) who made a ~2% loss on Tesla in a 5 day period.